
In het eerste deel van deze serie is het fundament voor observability uiteengezet en het belang ervan toegelicht. Deel twee gaat dieper in op de diverse mogelijkheden van observability en onderzoekt hoe dit concept effectief kan worden toegepast binnen jouw organisatie.
Observability-data 101
Observability draait om het verzamelen van data en daar effectief op kunnen acteren, maar wat betekent die informatie eigenlijk en waar komt het vandaan?
Er zijn eigenlijk drie belangrijke soorten datatypes:
- Logs: Dit zijn tekstregels met een tijdsaanduiding die afkomstig zijn uit een proces;
- Metrics: Dit zijn getallen die informatie geven over hoe goed een proces of onderdeel ervan functioneert;
- Traces: Hiermee wordt het pad gevolgd van een specifiek verzoek dat door één of meerdere processen loopt.
Neem bijvoorbeeld een Kubernetes-cluster. In dit geval kun je de gegevens onderverdelen in twee categorieën: systeemgegevens en applicatiegegevens.
Systeemeigen data laat zien hoe het cluster werkt, zoals logs en metrieken van essentiële Kubernetes-componenten (etcd, kubelet, API-server) of machinestatistieken. Dit is essentieel voor platformteams om effectief beheer uit te voeren.
Daartegenover staat applicatieniveau data, die inzicht biedt in het functioneren van specifieke applicaties. Denk hierbij aan metrieken en foutmeldingen van toepassingen als Apache Spark, of tracing-informatie tussen verschillende services waarmee bottlenecks of fouten kunnen worden opgespoord.
Daarnaast is het mogelijk om container-metrieken te verzamelen, zoals CPU-gebruik, geheugengebruik en disk-IO. Deze gegevens stellen ontwikkelaars en applicatiebeheerders in staat om problemen efficiënt op te lossen en de prestaties en beschikbaarheid te waarborgen.
Waar staat die data en hoe verzamel je het?
Voordat je kunt graven in de data, heb je een (centraal) platform nodig om je logs, metrics en traces in op te slaan.
Er zijn uiteraard volop mogelijkheden als het gaat om observability. In navolging van de vorige blog richten we ons hier vooral op de LGTM-stack als voorbeeld. Looks Good To Me!
Zodra je LGTM-stack staat, heb je nog data nodig uit je bronnen, zoals een Kubernetes-cluster en applicaties. Wij gebruiken:
- Fluent-Bit voor logging naar Loki
- Prometheus voor metrics naar Mimir
- Alloy voor traces naar Tempo
- OpenTelemetry als framework om traces te verzamelen en naar Alloy te sturen
Tip: Alloy kan ook logging en metrics verzamelen en doorsturen, en je kunt policies instellen om data selectief te verzenden. Het is een veelzijdige tool voor data-pipelines.
Wat doe je met die data?
Met deze data kun je snel inzichten opdoen en actie ondernemen bij problemen. Zonder een goede observability-strategie kost dit veel tijd of is het in complexe omgevingen vrijwel niet handmatig te doen.
Een voorbeeld: Verwerkingstijden
Ontwikkelaars willen weten hoelang verzoeken precies duren die via twee applicaties lopen: een uploadservice voor klantdata en een CSV-processor die die data verder verwerkt. Op dit moment weten ze alleen dat het verwerken van een gemiddeld CSV-bestand ongeveer 7 seconden duurt, door simpelweg de begin- en eindtijden in de logs van beide applicaties te vergelijken.
Dat vinden ze aan de lange kant en daarom zoeken ze naar manieren om het proces te verbeteren, maar waar begin je? Je kunt bijvoorbeeld bij elke stap in het proces een logregel toevoegen, zodat je precies ziet welke stap hoe lang duurt. Dat helpt al, maar misschien kan het efficiënter. Hier komt tracing om de hoek kijken. Tracing legt automatisch per stap vast hoeveel tijd iets kost, inclusief een tracing-ID die alle stappen aan elkaar koppelt. Zo kun je eenvoudig processen volgen over meerdere applicaties heen.
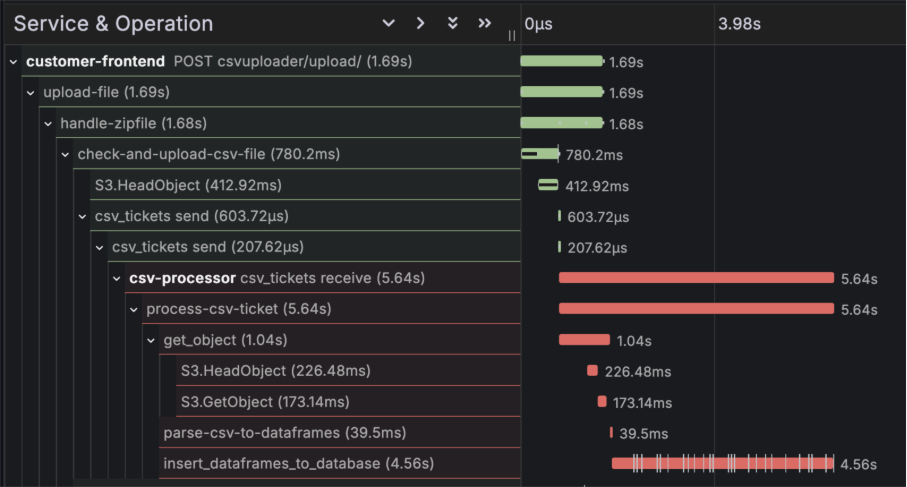
Op de bovenstaande afbeelding is een trace uit Grafana weergegeven. Hieruit blijkt dat de stap “insert_dataframes_to_database” het grootste deel van de verwerkingstijd van het CSV-bestand inneemt. Hierdoor kan een ontwikkelaar zich meteen richten op dit specifieke onderdeel van de code, zonder te hoeven raden waar de meeste tijdswinst mogelijk is.
Tracing is echter niet zonder kosten. Applicaties dienen namelijk te worden uitgerust met instrumentatie om tracing mogelijk te maken. Moderne technologieën zoals zero-code instrumentation van OTEL en instrumentatie-injectie via de otel operator bieden hiervoor efficiënte oplossingen.
Er zijn innovatieve projecten waarmee je met eBPF automatisch traces kunt genereren, zonder dat je jouw code hoeft aan te passen. Een goed voorbeeld hiervan is Grafana Beyla. Wil je echter zeer gedetailleerde procesinformatie in je traces of spans, dan zul je wat extra werk moeten doen om dit voor elkaar te krijgen.
Observability gaat verder dan alleen het implementeren van een LGTM-stack; het vraagt ook om inzicht in de onderliggende uitdagingen en het kiezen van tools die goed aansluiten bij wat gebruikers nodig hebben. Een doordacht dashboard, passende software of traces die zijn aangevuld met essentiële informatie kunnen het verschil betekenen tussen snelle probleemoplossing en een moeizaam proces.
Hoe nu verder?
Nu we een solide basis hebben gelegd rondom observability, kunnen we een stap verder zetten: naar multi-cluster observability.
Het monitoren van één Kubernetes-cluster is interessant, maar de kans is groot dat je meerdere clusters hebt draaien. Dit geldt zeker als je een duidelijke scheiding wilt aanbrengen tussen productie en andere omgevingen.
Gelukkig heb je met een werkende LGTM-stack het meeste al geregeld. Het enige wat nodig is vanuit de zendende instrumentatie, is het toevoegen van een label om elk cluster te identificeren. De dashboards kun je vervolgens aanpassen zodat ze de cluster-tag als filter gebruiken.
Zo wordt het mogelijk om bijvoorbeeld te zoeken op een specifieke term (zoals “error”) en direct te zien in welke clusters en bijbehorende namespaces deze term voorkomt.
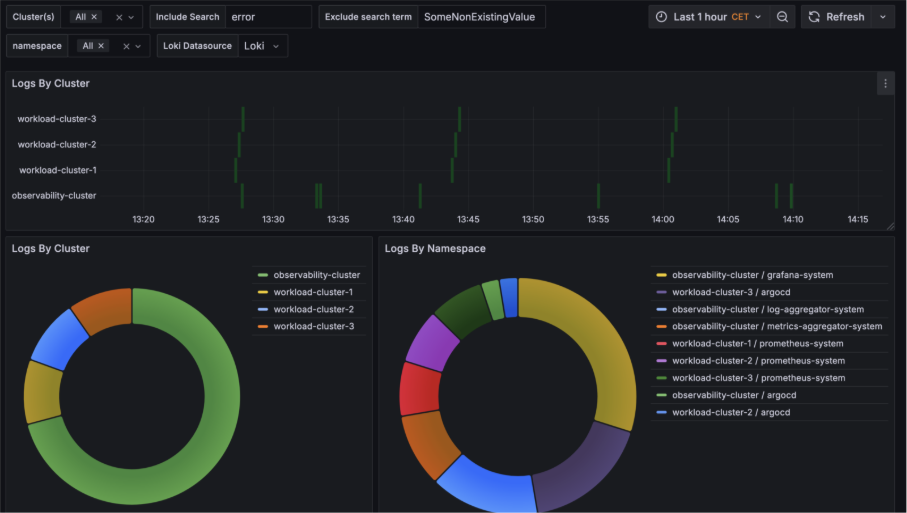
Een mogelijke use-case is dat een platform engineer een nieuw team wil onboarden op een van de clusters. Door gebruik te maken van een dashboard met relevante query's kan de engineer direct inzicht verkrijgen in welk cluster het meest geschikt is voor de beoogde workload van het team.
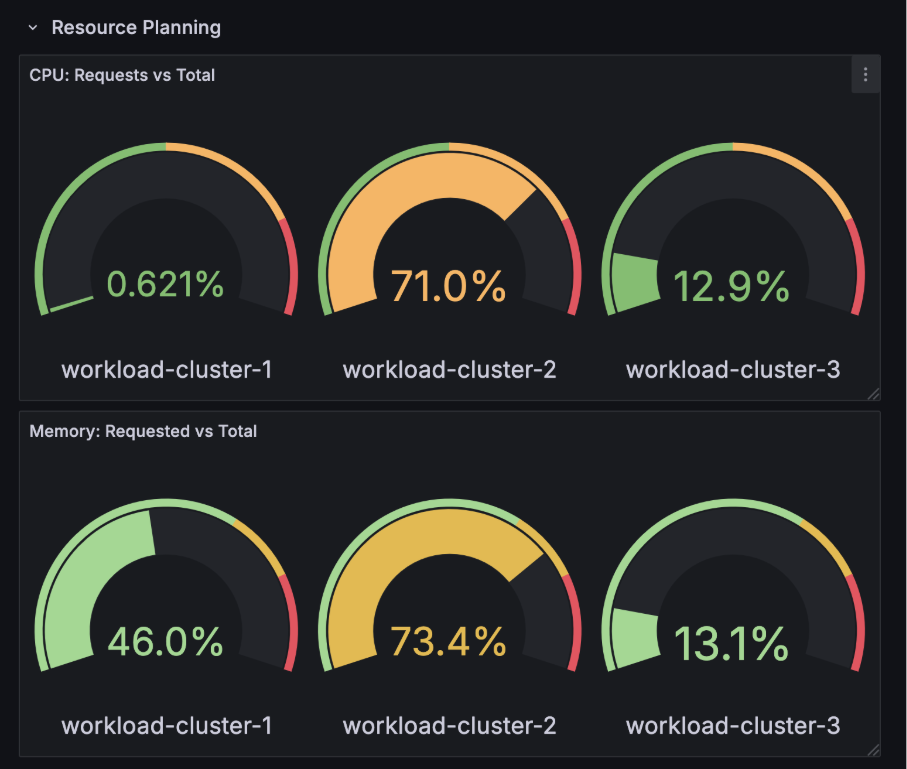
In het onderstaande voorbeeld zouden cluster 1 en 3 goede kandidaten zijn voor een grote workload.
Conclusie
Dit blog laat zien dat observability ontstaat door het gebruik van data, dashboards en een observability-stack. Door deze strategie uit te breiden naar meerdere clusters wordt de kracht ervan goed zichtbaar. Het is bovendien essentieel om vooraf te bepalen wat je precies wilt observeren en welk detailniveau daarvoor nodig is; zo kun je problemen doelgericht aanpakken.
In sommige situaties volstaat standaard observability niet en is extra informatie over metrics en tracing nodig, bijvoorbeeld voor inzicht op hoog niveau of snelle analyses. Gelukkig zijn er tegenwoordig veel betere tools beschikbaar, waardoor het toevoegen van deze observability-mogelijkheden steeds eenvoudiger wordt.